Last year, we published the “Elixxir BetaNet Nodes Guide” which stated nodes would require a “500 Megabit+” internet connection, but really leaning towards 1Gbit. Back when we published those specifications, there was concern because those numbers are not achievable for many, so the team worked to find a solution .
The previous requirement was a result of how nodes communicate so the Elixxir developers found a better way. Node to node comms were previously written to use unary communications rather than streaming communications. Now nodes communicate via streaming comms, greatly reducing the bandwidth requirements. We realize some people are still not able to meet these requirements but a reduction from 1Gbit to 500Mbit+ to 100Mbit allows for many more people to participate.
Ben recently published the revised node requirements. Today I’d like you to see how and why we require 100Mbit internet connection.
First the how. In the NodeLab I used a team of 5 nodes to complete 11 rounds. A round consists of the precomutation and the real time phases to deliver 10,000 messages, with the precomputation taking the bulk of the time. Each set of 11 rounds was conducted using 1Gbit, 500Mbit, 250Mbit, 100Mbit, 50Mbit and 10Mbit network speeds. The network in the NodeLab is 1Gbit LAN so I used Linux Traffic Control and Hierarchical Token Bucket to limit the bandwidth of the ports which the nodes communicate over.
The results can be seen in the following graph.
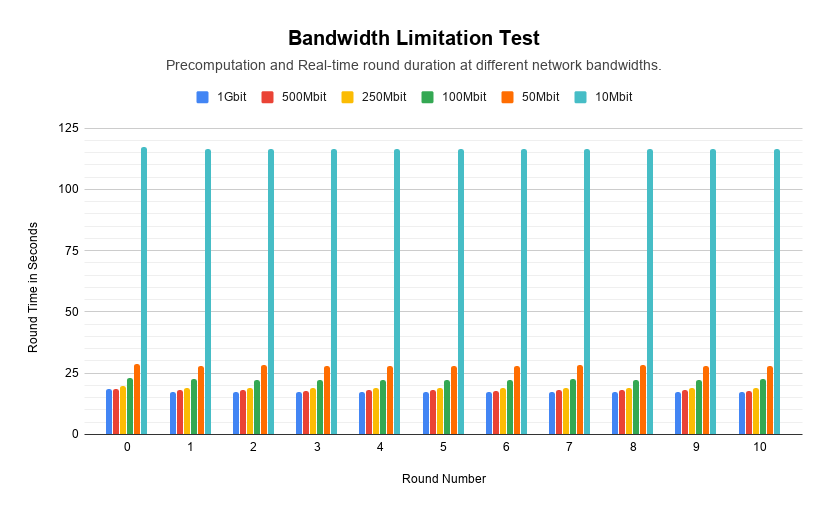
Now for the why 100Mbits.
Like most mix networks, the Elixxir protocol operates sequentially. A batch of messages must be processed by each node in a team order. By moving to streaming comms, a node can start on a batch before the entirety has been received. This means that as long as the transmission of data from one node to the other is faster than the cryptography, the time it takes to transfer the data does not factor at all into how long the round takes.
From our testing we discovered that for a 10k batch with 4096 bit messages, that limit is roughly 100 megabits.
xx network was able to solve the problem of slow secure messaging by not doing everything in real time and by moving most of the cryptographic work to precomputation. Unfortunately there is nothing we can do about how quickly it actually takes to send data across the internet.
I hope this helps everyone understand how we came to the decision and why we have the requirements we do.