On Wednesday 10/7/2020 we put out an update which moved operations from a 2048 bit prime to a 4096 bit prime. This upgrade had always been in the roadmap, but was pushed up to deal with a large number of nodes running under specced on cheap hardware, many of which within the same data centers.
This created three issues which we were hoping the 4k prime update would address.
- Running a large portion of the network through a single host can allow that hosting company to censor the network
- The nodes running on these cheap VPSs do not meet the specs, and as the network matures, they will not perform
- This situation is unfair to those who are committed to the network and have provided the requested hardware.
While average precomputation times with 4K primes on GPUs are 8 times faster than CPU nodes, we discovered that a team with one slow node and two fast nodes is slowed down by much more than 1/3rd [1]. We have verified this property in the NodeLab, as you can see below.
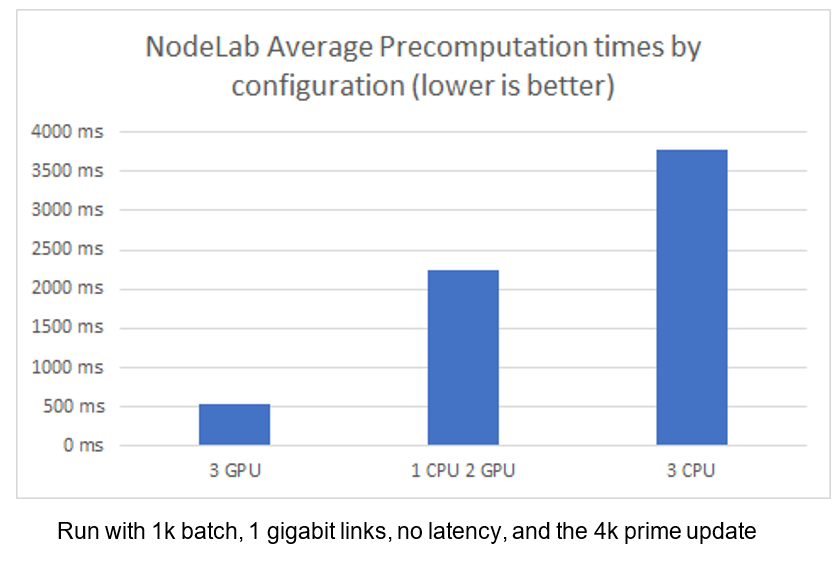
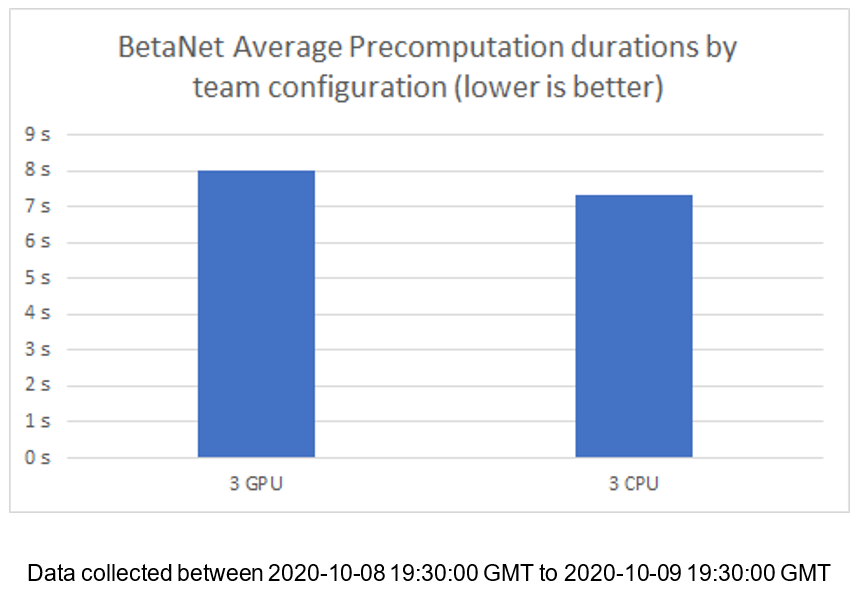
The resulting numbers on the live network were even worse than above because those nodes running in data centers are all very closely located. So their reduced latency with each other, combined with this effect, has made the final performance numbers of CPU nodes vs GPU nodes not useful for identifying underperforming nodes given the current betanet properties. As you can see below, our sample happens to show known GPU-only nodes as being slower than known CPU-only nodes due to this latency discrepancy.
So What do we do now?
Until full decentralization, the xx network team will be giving this topic more care. We will release an update to the dashboard which lists the service provider for every node[2] and will require the disclosure of planned service providers in the application process for future nodes, and not accept nodes using an over represented service provider.
The hardest part of this process is handling currently problematic nodes. We have separated all nodes on the network into the following 4 groups:
- High Concern: Nodes running in CPU mode on an over-represented service provider (27 Nodes)
- Moderate Concern: Node running on an over-represented service provider in GPU mode (10 Nodes)
- Minimal Concern: Node running in non over-represented service provider in CPU mode (19)
- No Concern: Nodes running in GPU mode on an non over-represented service provider. (116)
We have disabled all nodes of high concern as of today, and have reached out to them. We will require them to make changes to continue operating as part of the network. Before any nodes are kicked from the network or lose compensation, the issues will be presented to the community for input.
For nodes of Moderate Concern, we expect no action will be needed from the majority of them. We would like to avoid punishing them for happening to choose the same provider as others, so unless the problem persists we are inclined to allow them to stay.
For nodes of Minimal Concern, we don’t expect them to need to make any changes. CPU nodes are more likely to have performance issues down the road because they are not our build targets, so there is simply a little more risk. These nodes will be contacted in the coming days because their issues could be configuration issues.
And nodes of No Concern are in good standing. We are pleased that a significant majority of node operators have taken our request to heart and are so invested in supporting the network.
The groups can be found here, and any node who needs to make changes has already been notified over email.
Long Term
In the long term, we hope this process is handled by decentralized governance. This issue plagues most blockchains and many simply don’t pay much attention to it. For example, Bitcoin is overly centralized in China currently. In the long term, the solution we see is for decentralized governance to take a more active role in adding nodes to the network, allowing the users of the network to vote and make intelligent decisions about nodes.
Compensation Fairness
The elephant in the room is the disparity in costs over the past 3 months between operators of No Concern and those of High Concern. We feel that handling this issue inappropriately would place significant strain on the community and will do our best to make sure nodes feel whole. We understand that an answer to this question is needed, and continually saying “soon” rings hollow, but unfortunately we do not have a concrete plan yet.
Process
Due to the potentially complex nature of these issues, we will be handling individual cases with node operators via Email. If you have any questions about your specific case please email us at [email protected]. We of course encourage community discussion and feedback, and hope you will use public forums to discuss, process, and advise us on your opinions.
New Bugs
A new bug where nodes will sometimes get stuck has been introduced with this update. The occurrence of this bug will not impact compensation. The team is working on finding a solution and expects to release a hotfix shortly.
Footnotes
[1] The underlying idea with 4K primes was that as we increase the requirements of the network, those nodes who do not meet spec would be immediately obvious and could be handled. Unfortunately, if a slow node is feeding data to faster nodes, the faster nodes are only able to operate at the rate which the slower gives it input. While we can still discover slower nodes over time, the network latencies in the current betanet make it impossible to draw clear conclusions right now.
[2]We have used a “whois” IP lookup service to determine the hosting provider for an IP

